2.5 KiB
manga translator
get japanese manga from url to translate manga image using SickZil(tensorflow model), ocr(pytesseract ocr and nhocr) and googletrans
This project code is still under processing on the colab environment. For use, run colab in below url. https://colab.research.google.com/drive/1XbR7fNXtT4TGlLI1FBcCQv7Gj5mlDvwb?usp=sharing
result




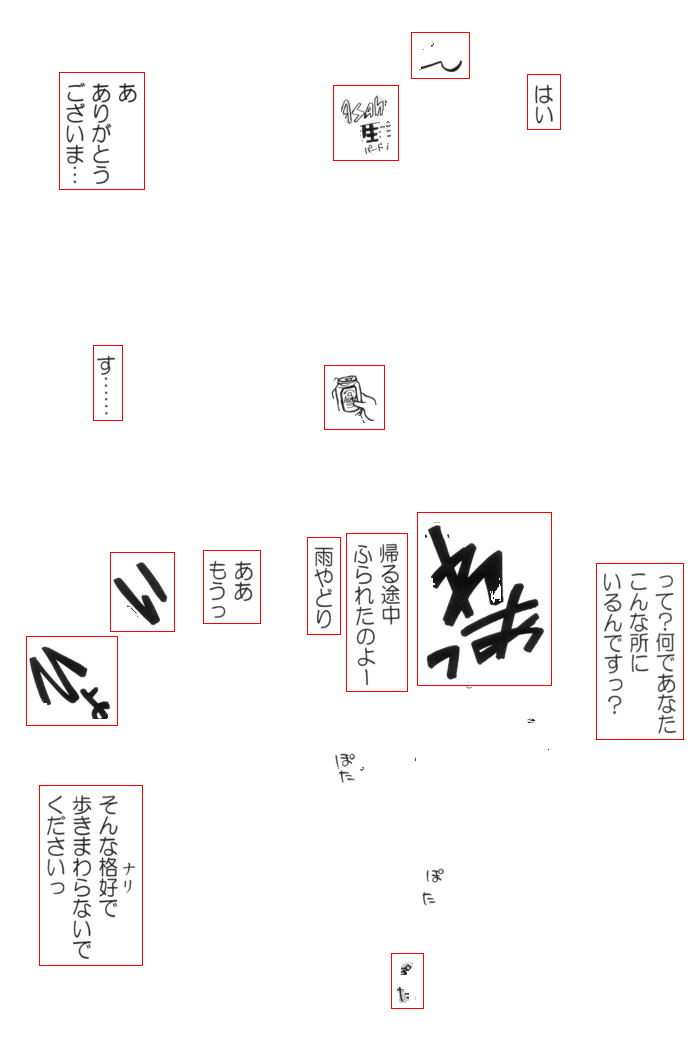


Workflow
- use gallery-dl to get managa from url
- do text segmentation from manga image using SickZil
- use opencv to crop text image based on text segmentation results
- get text from image using pytesseract ocr and nhocr
- translating using googletrans
- use pil to place translated text
Supported Languages (for destination translation)
For translating, it uses google trans. It supports : afrikaans, albanian, amharic, arabic, armenian, azerbaijani, basque, belarusian, bengali, bosnian, bulgarian, catalan, chichewa, chinese (simplified), chinese (traditional), corsican, croatian, czech, danish, dutch, english, esperanto, estonian, filipino, filipino, finnish, french, frisian, galician, georgian, german, greek, gujarati, haitian creole, hausa, hawaiian, hindi, hungarian, icelandic, igbo, indonesian, irish, italian, japanese, kazakh, khmer, korean, kurdish (kurmanji), kyrgyz, lao, latin, latvian, lithuanian, luxembourgish, macedonian, malagasy, malay, malayalam, maltese, maori, marathi, mongolian, myanmar (burmese), nepali, norwegian, pashto, persian, polish, portuguese, punjabi, romanian, russian, samoan, scots gaelic, serbian, sesotho, shona, sindhi, sinhala, slovak, slovenian, somali, spanish, sundanese, swahili, swedish, tajik, tamil, thai, turkish, ukrainian, urdu, uzbek, vietnamese, welsh, xhosa, yiddish, yoruba, zulu
Supported url
gallery-dl is used to download. Its support sites are: