57 KiB
| title | teaser | menu | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Rule-based matching | Find phrases and tokens, and match entities |
|
Compared to using regular expressions on raw text, spaCy's rule-based matcher
engines and components not only let you find you the words and phrases you're
looking for – they also give you access to the tokens within the document and
their relationships. This means you can easily access and analyze the
surrounding tokens, merge spans into single tokens or add entries to the named
entities in doc.ents.
For complex tasks, it's usually better to train a statistical entity recognition model. However, statistical models require training data, so for many situations, rule-based approaches are more practical. This is especially true at the start of a project: you can use a rule-based approach as part of a data collection process, to help you "bootstrap" a statistical model.
Training a model is useful if you have some examples and you want your system to be able to generalize based on those examples. It works especially well if there are clues in the local context. For instance, if you're trying to detect person or company names, your application may benefit from a statistical named entity recognition model.
Rule-based systems are a good choice if there's a more or less finite number of examples that you want to find in the data, or if there's a very clear, structured pattern you can express with token rules or regular expressions. For instance, country names, IP addresses or URLs are things you might be able to handle well with a purely rule-based approach.
You can also combine both approaches and improve a statistical model with rules to handle very specific cases and boost accuracy. For details, see the section on rule-based entity recognition.
The PhraseMatcher is useful if you already have a large terminology list or
gazetteer consisting of single or multi-token phrases that you want to find
exact instances of in your data. As of spaCy v2.1.0, you can also match on the
LOWER attribute for fast and case-insensitive matching.
The Matcher isn't as blazing fast as the PhraseMatcher, since it compares
across individual token attributes. However, it allows you to write very
abstract representations of the tokens you're looking for, using lexical
attributes, linguistic features predicted by the model, operators, set
membership and rich comparison. For example, you can find a noun, followed by a
verb with the lemma "love" or "like", followed by an optional determiner and
another token that's at least ten characters long.
Token-based matching
spaCy features a rule-matching engine, the Matcher, that
operates over tokens, similar to regular expressions. The rules can refer to
token annotations (e.g. the token text or tag_, and flags (e.g. IS_PUNCT).
The rule matcher also lets you pass in a custom callback to act on matches – for
example, to merge entities and apply custom labels. You can also associate
patterns with entity IDs, to allow some basic entity linking or disambiguation.
To match large terminology lists, you can use the
PhraseMatcher, which accepts Doc objects as match
patterns.
Adding patterns
Let's say we want to enable spaCy to find a combination of three tokens:
- A token whose lowercase form matches "hello", e.g. "Hello" or "HELLO".
- A token whose
is_punctflag is set toTrue, i.e. any punctuation. - A token whose lowercase form matches "world", e.g. "World" or "WORLD".
[{"LOWER": "hello"}, {"IS_PUNCT": True}, {"LOWER": "world"}]
When writing patterns, keep in mind that each dictionary represents one token. If spaCy's tokenization doesn't match the tokens defined in a pattern, the pattern is not going to produce any results. When developing complex patterns, make sure to check examples against spaCy's tokenization:
doc = nlp("A complex-example,!")
print([token.text for token in doc])
First, we initialize the Matcher with a vocab. The matcher must always share
the same vocab with the documents it will operate on. We can now call
matcher.add() with an ID and our custom pattern. The
second argument lets you pass in an optional callback function to invoke on a
successful match. For now, we set it to None.
### {executable="true"}
import spacy
from spacy.matcher import Matcher
nlp = spacy.load("en_core_web_sm")
matcher = Matcher(nlp.vocab)
# Add match ID "HelloWorld" with no callback and one pattern
pattern = [{"LOWER": "hello"}, {"IS_PUNCT": True}, {"LOWER": "world"}]
matcher.add("HelloWorld", None, pattern)
doc = nlp("Hello, world! Hello world!")
matches = matcher(doc)
for match_id, start, end in matches:
string_id = nlp.vocab.strings[match_id] # Get string representation
span = doc[start:end] # The matched span
print(match_id, string_id, start, end, span.text)
The matcher returns a list of (match_id, start, end) tuples – in this case,
[('15578876784678163569', 0, 2)], which maps to the span doc[0:2] of our
original document. The match_id is the hash value of
the string ID "HelloWorld". To get the string value, you can look up the ID in
the StringStore.
for match_id, start, end in matches:
string_id = nlp.vocab.strings[match_id] # 'HelloWorld'
span = doc[start:end] # The matched span
Optionally, we could also choose to add more than one pattern, for example to also match sequences without punctuation between "hello" and "world":
matcher.add("HelloWorld", None,
[{"LOWER": "hello"}, {"IS_PUNCT": True}, {"LOWER": "world"}],
[{"LOWER": "hello"}, {"LOWER": "world"}])
By default, the matcher will only return the matches and not do anything
else, like merge entities or assign labels. This is all up to you and can be
defined individually for each pattern, by passing in a callback function as the
on_match argument on add(). This is useful, because it lets you write
entirely custom and pattern-specific logic. For example, you might want to
merge some patterns into one token, while adding entity labels for other
pattern types. You shouldn't have to create different matchers for each of those
processes.
Available token attributes
The available token pattern keys correspond to a number of
Token attributes. The supported attributes for
rule-based matching are:
| Attribute | Type | Description |
|---|---|---|
ORTH |
unicode | The exact verbatim text of a token. |
TEXT 2.1 |
unicode | The exact verbatim text of a token. |
LOWER |
unicode | The lowercase form of the token text. |
LENGTH |
int | The length of the token text. |
IS_ALPHA, IS_ASCII, IS_DIGIT |
bool | Token text consists of alphabetic characters, ASCII characters, digits. |
IS_LOWER, IS_UPPER, IS_TITLE |
bool | Token text is in lowercase, uppercase, titlecase. |
IS_PUNCT, IS_SPACE, IS_STOP |
bool | Token is punctuation, whitespace, stop word. |
LIKE_NUM, LIKE_URL, LIKE_EMAIL |
bool | Token text resembles a number, URL, email. |
POS, TAG, DEP, LEMMA, SHAPE |
unicode | The token's simple and extended part-of-speech tag, dependency label, lemma, shape. |
ENT_TYPE |
unicode | The token's entity label. |
_ 2.1 |
dict | Properties in custom extension attributes. |
No, it shouldn't. spaCy will normalize the names internally and
{"LOWER": "text"} and {"lower": "text"} will both produce the same result.
Using the uppercase version is mostly a convention to make it clear that the
attributes are "special" and don't exactly map to the token attributes like
Token.lower and Token.lower_.
spaCy can't provide access to all of the attributes because the Matcher loops
over the Cython data, not the Python objects. Inside the matcher, we're dealing
with a TokenC struct – we don't have an instance
of Token. This means that all of the attributes that refer to
computed properties can't be accessed.
The uppercase attribute names like LOWER or IS_PUNCT refer to symbols from
the
spacy.attrs
enum table. They're passed into a function that essentially is a big case/switch
statement, to figure out which struct field to return. The same attribute
identifiers are used in Doc.to_array, and a few other
places in the code where you need to describe fields like this.
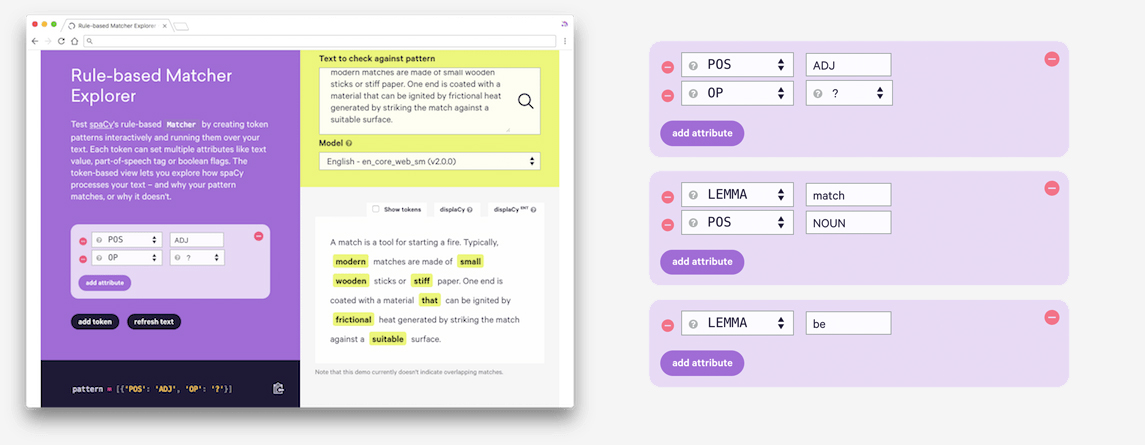
The Matcher Explorer lets you test the
rule-based Matcher by creating token patterns interactively and running them
over your text. Each token can set multiple attributes like text value,
part-of-speech tag or boolean flags. The token-based view lets you explore how
spaCy processes your text – and why your pattern matches, or why it doesn't.
Extended pattern syntax and attributes
Instead of mapping to a single value, token patterns can also map to a dictionary of properties. For example, to specify that the value of a lemma should be part of a list of values, or to set a minimum character length. The following rich comparison attributes are available:
Example
# Matches "love cats" or "likes flowers" pattern1 = [{"LEMMA": {"IN": ["like", "love"]}}, {"POS": "NOUN"}] # Matches tokens of length >= 10 pattern2 = [{"LENGTH": {">=": 10}}]
| Attribute | Value Type | Description |
|---|---|---|
IN |
any | Attribute value is member of a list. |
NOT_IN |
any | Attribute value is not member of a list. |
==, >=, <=, >, < |
int, float | Attribute value is equal, greater or equal, smaller or equal, greater or smaller. |
Regular expressions
In some cases, only matching tokens and token attributes isn't enough – for example, you might want to match different spellings of a word, without having to add a new pattern for each spelling.
pattern = [{"TEXT": {"REGEX": "^[Uu](\\.?|nited)$"}},
{"TEXT": {"REGEX": "^[Ss](\\.?|tates)$"}},
{"LOWER": "president"}]
The REGEX operator allows defining rules for any attribute string value,
including custom attributes. It always needs to be applied to an attribute like
TEXT, LOWER or TAG:
# Match different spellings of token texts
pattern = [{"TEXT": {"REGEX": "deff?in[ia]tely"}}]
# Match tokens with fine-grained POS tags starting with 'V'
pattern = [{"TAG": {"REGEX": "^V"}}]
# Match custom attribute values with regular expressions
pattern = [{"_": {"country": {"REGEX": "^[Uu](nited|\\.?) ?[Ss](tates|\\.?)$"}}}]
When using the REGEX operator, keep in mind that it operates on single
tokens, not the whole text. Each expression you provide will be matched on a
token. If you need to match on the whole text instead, see the details on
regex matching on the whole text.
Matching regular expressions on the full text
If your expressions apply to multiple tokens, a simple solution is to match on
the doc.text with re.finditer and use the
Doc.char_span method to create a Span from the
character indices of the match. If the matched characters don't map to one or
more valid tokens, Doc.char_span returns None.
What's a valid token sequence?
In the example, the expression will also match
"US"in"USA". However,"USA"is a single token andSpanobjects are sequences of tokens. So"US"cannot be its own span, because it does not end on a token boundary.
### {executable="true"}
import spacy
import re
nlp = spacy.load("en_core_web_sm")
doc = nlp("The United States of America (USA) are commonly known as the United States (U.S. or US) or America.")
expression = r"[Uu](nited|\\.?) ?[Ss](tates|\\.?)"
for match in re.finditer(expression, doc.text):
start, end = match.span()
span = doc.char_span(start, end)
# This is a Span object or None if match doesn't map to valid token sequence
if span is not None:
print("Found match:", span.text)
In some cases, you might want to expand the match to the closest token
boundaries, so you can create a Span for "USA", even though only the
substring "US" is matched. You can calculate this using the character offsets
of the tokens in the document, available as
Token.idx. This lets you create a list of valid token
start and end boundaries and leaves you with a rather basic algorithmic problem:
Given a number, find the next lowest (start token) or the next highest (end
token) number that's part of a given list of numbers. This will be the closest
valid token boundary.
There are many ways to do this and the most straightforward one is to create a
dict keyed by characters in the Doc, mapped to the token they're part of. It's
easy to write and less error-prone, and gives you a constant lookup time: you
only ever need to create the dict once per Doc.
chars_to_tokens = {}
for token in doc:
for i in range(token.idx, token.idx + len(token.text)):
chars_to_tokens[i] = token.i
You can then look up character at a given position, and get the index of the
corresponding token that the character is part of. Your span would then be
doc[token_start:token_end]. If a character isn't in the dict, it means it's
the (white)space tokens are split on. That hopefully shouldn't happen, though,
because it'd mean your regex is producing matches with leading or trailing
whitespace.
### {highlight="5-8"}
span = doc.char_span(start, end)
if span is not None:
print("Found match:", span.text)
else:
start_token = chars_to_tokens.get(start)
end_token = chars_to_tokens.get(end)
if start_token is not None and end_token is not None:
span = doc[start_token:end_token + 1]
print("Found closest match:", span.text)
Operators and quantifiers
The matcher also lets you use quantifiers, specified as the 'OP' key.
Quantifiers let you define sequences of tokens to be matched, e.g. one or more
punctuation marks, or specify optional tokens. Note that there are no nested or
scoped quantifiers – instead, you can build those behaviors with on_match
callbacks.
| OP | Description |
|---|---|
! |
Negate the pattern, by requiring it to match exactly 0 times. |
? |
Make the pattern optional, by allowing it to match 0 or 1 times. |
+ |
Require the pattern to match 1 or more times. |
* |
Allow the pattern to match zero or more times. |
Example
pattern = [{"LOWER": "hello"}, {"IS_PUNCT": True, "OP": "?"}]
In versions before v2.1.0, the semantics of the + and * operators behave
inconsistently. They were usually interpreted "greedily", i.e. longer matches
are returned where possible. However, if you specify two + and * patterns in
a row and their matches overlap, the first operator will behave non-greedily.
This quirk in the semantics is corrected in spaCy v2.1.0.
Using wildcard token patterns
While the token attributes offer many options to write highly specific patterns,
you can also use an empty dictionary, {} as a wildcard representing any
token. This is useful if you know the context of what you're trying to match,
but very little about the specific token and its characters. For example, let's
say you're trying to extract people's user names from your data. All you know is
that they are listed as "User name: {username}". The name itself may contain any
character, but no whitespace – so you'll know it will be handled as one token.
[{"ORTH": "User"}, {"ORTH": "name"}, {"ORTH": ":"}, {}]
Validating and debugging patterns
The Matcher can validate patterns against a JSON schema with the option
validate=True. This is useful for debugging patterns during development, in
particular for catching unsupported attributes.
### {executable="true"}
import spacy
from spacy.matcher import Matcher
nlp = spacy.load("en_core_web_sm")
matcher = Matcher(nlp.vocab, validate=True)
# Add match ID "HelloWorld" with unsupported attribute CASEINSENSITIVE
pattern = [{"LOWER": "hello"}, {"IS_PUNCT": True}, {"CASEINSENSITIVE": "world"}]
matcher.add("HelloWorld", None, pattern)
# 🚨 Raises an error:
# MatchPatternError: Invalid token patterns for matcher rule 'HelloWorld'
# Pattern 0:
# - Additional properties are not allowed ('CASEINSENSITIVE' was unexpected) [2]
Adding on_match rules
To move on to a more realistic example, let's say you're working with a large
corpus of blog articles, and you want to match all mentions of "Google I/O"
(which spaCy tokenizes as ['Google', 'I', '/', 'O']). To be safe, you only
match on the uppercase versions, in case someone has written it as "Google i/o".
### {executable="true"}
from spacy.lang.en import English
from spacy.matcher import Matcher
from spacy.tokens import Span
nlp = English()
matcher = Matcher(nlp.vocab)
def add_event_ent(matcher, doc, i, matches):
# Get the current match and create tuple of entity label, start and end.
# Append entity to the doc's entity. (Don't overwrite doc.ents!)
match_id, start, end = matches[i]
entity = Span(doc, start, end, label="EVENT")
doc.ents += (entity,)
print(entity.text)
pattern = [{"ORTH": "Google"}, {"ORTH": "I"}, {"ORTH": "/"}, {"ORTH": "O"}]
matcher.add("GoogleIO", add_event_ent, pattern)
doc = nlp("This is a text about Google I/O")
matches = matcher(doc)
A very similar logic has been implemented in the built-in
EntityRuler by the way. It also takes care of handling
overlapping matches, which you would otherwise have to take care of yourself.
Tip: Visualizing matches
When working with entities, you can use displaCy to quickly generate a NER visualization from your updated
Doc, which can be exported as an HTML file:from spacy import displacy html = displacy.render(doc, style="ent", page=True, options={"ents": ["EVENT"]})For more info and examples, see the usage guide on visualizing spaCy.
We can now call the matcher on our documents. The patterns will be matched in the order they occur in the text. The matcher will then iterate over the matches, look up the callback for the match ID that was matched, and invoke it.
doc = nlp(YOUR_TEXT_HERE)
matcher(doc)
When the callback is invoked, it is passed four arguments: the matcher itself, the document, the position of the current match, and the total list of matches. This allows you to write callbacks that consider the entire set of matched phrases, so that you can resolve overlaps and other conflicts in whatever way you prefer.
| Argument | Type | Description |
|---|---|---|
matcher |
Matcher |
The matcher instance. |
doc |
Doc |
The document the matcher was used on. |
i |
int | Index of the current match (matches[i]). |
matches |
list | A list of (match_id, start, end) tuples, describing the matches. A match tuple describes a span doc[start:end]. |
Using custom pipeline components
Let's say your data also contains some annoying pre-processing artifacts, like
leftover HTML line breaks (e.g. <br> or <BR/>). To make your text easier to
analyze, you want to merge those into one token and flag them, to make sure you
can ignore them later. Ideally, this should all be done automatically as you
process the text. You can achieve this by adding a
custom pipeline component
that's called on each Doc object, merges the leftover HTML spans and sets an
attribute bad_html on the token.
### {executable="true"}
import spacy
from spacy.matcher import Matcher
from spacy.tokens import Token
# We're using a class because the component needs to be initialised with
# the shared vocab via the nlp object
class BadHTMLMerger(object):
def __init__(self, nlp):
# Register a new token extension to flag bad HTML
Token.set_extension("bad_html", default=False)
self.matcher = Matcher(nlp.vocab)
self.matcher.add(
"BAD_HTML",
None,
[{"ORTH": "<"}, {"LOWER": "br"}, {"ORTH": ">"}],
[{"ORTH": "<"}, {"LOWER": "br/"}, {"ORTH": ">"}],
)
def __call__(self, doc):
# This method is invoked when the component is called on a Doc
matches = self.matcher(doc)
spans = [] # Collect the matched spans here
for match_id, start, end in matches:
spans.append(doc[start:end])
with doc.retokenize() as retokenizer:
for span in spans:
retokenizer.merge(span)
for token in span:
token._.bad_html = True # Mark token as bad HTML
return doc
nlp = spacy.load("en_core_web_sm")
html_merger = BadHTMLMerger(nlp)
nlp.add_pipe(html_merger, last=True) # Add component to the pipeline
doc = nlp("Hello<br>world! <br/> This is a test.")
for token in doc:
print(token.text, token._.bad_html)
Instead of hard-coding the patterns into the component, you could also make it take a path to a JSON file containing the patterns. This lets you reuse the component with different patterns, depending on your application:
html_merger = BadHTMLMerger(nlp, path="/path/to/patterns.json")
For more details and examples of how to create custom pipeline components and extension attributes, see the usage guide.
Example: Using linguistic annotations
Let's say you're analyzing user comments and you want to find out what people are saying about Facebook. You want to start off by finding adjectives following "Facebook is" or "Facebook was". This is obviously a very rudimentary solution, but it'll be fast, and a great way to get an idea for what's in your data. Your pattern could look like this:
[{"LOWER": "facebook"}, {"LEMMA": "be"}, {"POS": "ADV", "OP": "*"}, {"POS": "ADJ"}]
This translates to a token whose lowercase form matches "facebook" (like Facebook, facebook or FACEBOOK), followed by a token with the lemma "be" (for example, is, was, or 's), followed by an optional adverb, followed by an adjective. Using the linguistic annotations here is especially useful, because you can tell spaCy to match "Facebook's annoying", but not "Facebook's annoying ads". The optional adverb makes sure you won't miss adjectives with intensifiers, like "pretty awful" or "very nice".
To get a quick overview of the results, you could collect all sentences
containing a match and render them with the
displaCy visualizer. In the callback function, you'll have
access to the start and end of each match, as well as the parent Doc. This
lets you determine the sentence containing the match, doc[start : end.sent],
and calculate the start and end of the matched span within the sentence. Using
displaCy in "manual" mode lets you pass in a
list of dictionaries containing the text and entities to render.
### {executable="true"}
import spacy
from spacy import displacy
from spacy.matcher import Matcher
nlp = spacy.load("en_core_web_sm")
matcher = Matcher(nlp.vocab)
matched_sents = [] # Collect data of matched sentences to be visualized
def collect_sents(matcher, doc, i, matches):
match_id, start, end = matches[i]
span = doc[start:end] # Matched span
sent = span.sent # Sentence containing matched span
# Append mock entity for match in displaCy style to matched_sents
# get the match span by ofsetting the start and end of the span with the
# start and end of the sentence in the doc
match_ents = [{
"start": span.start_char - sent.start_char,
"end": span.end_char - sent.start_char,
"label": "MATCH",
}]
matched_sents.append({"text": sent.text, "ents": match_ents})
pattern = [{"LOWER": "facebook"}, {"LEMMA": "be"}, {"POS": "ADV", "OP": "*"},
{"POS": "ADJ"}]
matcher.add("FacebookIs", collect_sents, pattern) # add pattern
doc = nlp("I'd say that Facebook is evil. – Facebook is pretty cool, right?")
matches = matcher(doc)
# Serve visualization of sentences containing match with displaCy
# set manual=True to make displaCy render straight from a dictionary
# (if you're not running the code within a Jupyer environment, you can
# use displacy.serve instead)
displacy.render(matched_sents, style="ent", manual=True)
Example: Phone numbers
Phone numbers can have many different formats and matching them is often tricky. During tokenization, spaCy will leave sequences of numbers intact and only split on whitespace and punctuation. This means that your match pattern will have to look out for number sequences of a certain length, surrounded by specific punctuation – depending on the national conventions.
The IS_DIGIT flag is not very helpful here, because it doesn't tell us
anything about the length. However, you can use the SHAPE flag, with each d
representing a digit:
[{"ORTH": "("}, {"SHAPE": "ddd"}, {"ORTH": ")"}, {"SHAPE": "dddd"},
{"ORTH": "-", "OP": "?"}, {"SHAPE": "dddd"}]
This will match phone numbers of the format (123) 4567 8901 or (123)
4567-8901. To also match formats like (123) 456 789, you can add a second
pattern using 'ddd' in place of 'dddd'. By hard-coding some values, you can
match only certain, country-specific numbers. For example, here's a pattern to
match the most common formats of
international German numbers:
[{"ORTH": "+"}, {"ORTH": "49"}, {"ORTH": "(", "OP": "?"}, {"SHAPE": "dddd"},
{"ORTH": ")", "OP": "?"}, {"SHAPE": "dddddd"}]
Depending on the formats your application needs to match, creating an extensive set of rules like this is often better than training a model. It'll produce more predictable results, is much easier to modify and extend, and doesn't require any training data – only a set of test cases.
### {executable="true"}
import spacy
from spacy.matcher import Matcher
nlp = spacy.load("en_core_web_sm")
matcher = Matcher(nlp.vocab)
pattern = [{"ORTH": "("}, {"SHAPE": "ddd"}, {"ORTH": ")"}, {"SHAPE": "ddd"},
{"ORTH": "-", "OP": "?"}, {"SHAPE": "ddd"}]
matcher.add("PHONE_NUMBER", None, pattern)
doc = nlp("Call me at (123) 456 789 or (123) 456 789!")
print([t.text for t in doc])
matches = matcher(doc)
for match_id, start, end in matches:
span = doc[start:end]
print(span.text)
Example: Hashtags and emoji on social media
Social media posts, especially tweets, can be difficult to work with. They're very short and often contain various emoji and hashtags. By only looking at the plain text, you'll lose a lot of valuable semantic information.
Let's say you've extracted a large sample of social media posts on a specific
topic, for example posts mentioning a brand name or product. As the first step
of your data exploration, you want to filter out posts containing certain emoji
and use them to assign a general sentiment score, based on whether the expressed
emotion is positive or negative, e.g. 😀 or 😞. You also want to find, merge and
label hashtags like #MondayMotivation, to be able to ignore or analyze them
later.
Note on sentiment analysis
Ultimately, sentiment analysis is not always that easy. In addition to the emoji, you'll also want to take specific words into account and check the
subtreefor intensifiers like "very", to increase the sentiment score. At some point, you might also want to train a sentiment model. However, the approach described in this example is very useful for bootstrapping rules to collect training data. It's also an incredibly fast way to gather first insights into your data – with about 1 million tweets, you'd be looking at a processing time of under 1 minute.
By default, spaCy's tokenizer will split emoji into separate tokens. This means
that you can create a pattern for one or more emoji tokens. Valid hashtags
usually consist of a #, plus a sequence of ASCII characters with no
whitespace, making them easy to match as well.
### {executable="true"}
from spacy.lang.en import English
from spacy.matcher import Matcher
nlp = English() # We only want the tokenizer, so no need to load a model
matcher = Matcher(nlp.vocab)
pos_emoji = ["😀", "😃", "😂", "🤣", "😊", "😍"] # Positive emoji
neg_emoji = ["😞", "😠", "😩", "😢", "😭", "😒"] # Negative emoji
# Add patterns to match one or more emoji tokens
pos_patterns = [[{"ORTH": emoji}] for emoji in pos_emoji]
neg_patterns = [[{"ORTH": emoji}] for emoji in neg_emoji]
# Function to label the sentiment
def label_sentiment(matcher, doc, i, matches):
match_id, start, end = matches[i]
if doc.vocab.strings[match_id] == "HAPPY": # Don't forget to get string!
doc.sentiment += 0.1 # Add 0.1 for positive sentiment
elif doc.vocab.strings[match_id] == "SAD":
doc.sentiment -= 0.1 # Subtract 0.1 for negative sentiment
matcher.add("HAPPY", label_sentiment, *pos_patterns) # Add positive pattern
matcher.add("SAD", label_sentiment, *neg_patterns) # Add negative pattern
# Add pattern for valid hashtag, i.e. '#' plus any ASCII token
matcher.add("HASHTAG", None, [{"ORTH": "#"}, {"IS_ASCII": True}])
doc = nlp("Hello world 😀 #MondayMotivation")
matches = matcher(doc)
for match_id, start, end in matches:
string_id = doc.vocab.strings[match_id] # Look up string ID
span = doc[start:end]
print(string_id, span.text)
Because the on_match callback receives the ID of each match, you can use the
same function to handle the sentiment assignment for both the positive and
negative pattern. To keep it simple, we'll either add or subtract 0.1 points –
this way, the score will also reflect combinations of emoji, even positive and
negative ones.
With a library like Emojipedia,
we can also retrieve a short description for each emoji – for example, 😍's
official title is "Smiling Face With Heart-Eyes". Assigning it to a
custom attribute on
the emoji span will make it available as span._.emoji_desc.
from emojipedia import Emojipedia # Installation: pip install emojipedia
from spacy.tokens import Span # Get the global Span object
Span.set_extension("emoji_desc", default=None) # Register the custom attribute
def label_sentiment(matcher, doc, i, matches):
match_id, start, end = matches[i]
if doc.vocab.strings[match_id] == "HAPPY": # Don't forget to get string!
doc.sentiment += 0.1 # Add 0.1 for positive sentiment
elif doc.vocab.strings[match_id] == "SAD":
doc.sentiment -= 0.1 # Subtract 0.1 for negative sentiment
span = doc[start:end]
emoji = Emojipedia.search(span[0].text) # Get data for emoji
span._.emoji_desc = emoji.title # Assign emoji description
To label the hashtags, we can use a custom attribute set on the respective token:
### {executable="true"}
import spacy
from spacy.matcher import Matcher
from spacy.tokens import Token
nlp = spacy.load("en_core_web_sm")
matcher = Matcher(nlp.vocab)
# Add pattern for valid hashtag, i.e. '#' plus any ASCII token
matcher.add("HASHTAG", None, [{"ORTH": "#"}, {"IS_ASCII": True}])
# Register token extension
Token.set_extension("is_hashtag", default=False)
doc = nlp("Hello world 😀 #MondayMotivation")
matches = matcher(doc)
hashtags = []
for match_id, start, end in matches:
if doc.vocab.strings[match_id] == "HASHTAG":
hashtags.append(doc[start:end])
with doc.retokenize() as retokenizer:
for span in hashtags:
retokenizer.merge(span)
for token in span:
token._.is_hashtag = True
for token in doc:
print(token.text, token._.is_hashtag)
To process a stream of social media posts, we can use
Language.pipe, which will return a stream of Doc
objects that we can pass to Matcher.pipe.
docs = nlp.pipe(LOTS_OF_TWEETS)
matches = matcher.pipe(docs)
Efficient phrase matching
If you need to match large terminology lists, you can also use the
PhraseMatcher and create Doc objects
instead of token patterns, which is much more efficient overall. The Doc
patterns can contain single or multiple tokens.
Adding phrase patterns
### {executable="true"}
import spacy
from spacy.matcher import PhraseMatcher
nlp = spacy.load('en_core_web_sm')
matcher = PhraseMatcher(nlp.vocab)
terms = ["Barack Obama", "Angela Merkel", "Washington, D.C."]
# Only run nlp.make_doc to speed things up
patterns = [nlp.make_doc(text) for text in terms]
matcher.add("TerminologyList", None, *patterns)
doc = nlp("German Chancellor Angela Merkel and US President Barack Obama "
"converse in the Oval Office inside the White House in Washington, D.C.")
matches = matcher(doc)
for match_id, start, end in matches:
span = doc[start:end]
print(span.text)
Since spaCy is used for processing both the patterns and the text to be matched,
you won't have to worry about specific tokenization – for example, you can
simply pass in nlp("Washington, D.C.") and won't have to write a complex token
pattern covering the exact tokenization of the term.
To create the patterns, each phrase has to be processed with the nlp object.
If you have a model loaded, doing this in a loop or list comprehension can
easily become inefficient and slow. If you only need the tokenization and
lexical attributes, you can run nlp.make_doc
instead, which will only run the tokenizer. For an additional speed boost, you
can also use the nlp.tokenizer.pipe method, which will
process the texts as a stream.
- patterns = [nlp(term) for term in LOTS_OF_TERMS]
+ patterns = [nlp.make_doc(term) for term in LOTS_OF_TERMS]
+ patterns = list(nlp.tokenizer.pipe(LOTS_OF_TERMS))
Matching on other token attributes
By default, the PhraseMatcher will match on the verbatim token text, e.g.
Token.text. By setting the attr argument on initialization, you can change
which token attribute the matcher should use when comparing the phrase
pattern to the matched Doc. For example, using the attribute LOWER lets you
match on Token.lower and create case-insensitive match patterns:
### {executable="true"}
from spacy.lang.en import English
from spacy.matcher import PhraseMatcher
nlp = English()
matcher = PhraseMatcher(nlp.vocab, attr="LOWER")
patterns = [nlp.make_doc(name) for name in ["Angela Merkel", "Barack Obama"]]
matcher.add("Names", None, *patterns)
doc = nlp("angela merkel and us president barack Obama")
for match_id, start, end in matcher(doc):
print("Matched based on lowercase token text:", doc[start:end])
The examples here use nlp.make_doc to create Doc
object patterns as efficiently as possible and without running any of the other
pipeline components. If the token attribute you want to match on are set by a
pipeline component, make sure that the pipeline component runs when you
create the pattern. For example, to match on POS or LEMMA, the pattern Doc
objects need to have part-of-speech tags set by the tagger. You can either
call the nlp object on your pattern texts instead of nlp.make_doc, or use
nlp.disable_pipes to disable components
selectively.
Another possible use case is matching number tokens like IP addresses based on
their shape. This means that you won't have to worry about how those string will
be tokenized and you'll be able to find tokens and combinations of tokens based
on a few examples. Here, we're matching on the shapes ddd.d.d.d and
ddd.ddd.d.d:
### {executable="true"}
from spacy.lang.en import English
from spacy.matcher import PhraseMatcher
nlp = English()
matcher = PhraseMatcher(nlp.vocab, attr="SHAPE")
matcher.add("IP", None, nlp("127.0.0.1"), nlp("127.127.0.0"))
doc = nlp("Often the router will have an IP address such as 192.168.1.1 or 192.168.2.1.")
for match_id, start, end in matcher(doc):
print("Matched based on token shape:", doc[start:end])
In theory, the same also works for attributes like POS. For example, a pattern
nlp("I like cats") matched based on its part-of-speech tag would return a
match for "I love dogs". You could also match on boolean flags like IS_PUNCT
to match phrases with the same sequence of punctuation and non-punctuation
tokens as the pattern. But this can easily get confusing and doesn't have much
of an advantage over writing one or two token patterns.
Rule-based entity recognition
The EntityRuler is an exciting new component that lets you
add named entities based on pattern dictionaries, and makes it easy to combine
rule-based and statistical named entity recognition for even more powerful
models.
Entity Patterns
Entity patterns are dictionaries with two keys: "label", specifying the label
to assign to the entity if the pattern is matched, and "pattern", the match
pattern. The entity ruler accepts two types of patterns:
-
Phrase patterns for exact string matches (string).
{"label": "ORG", "pattern": "Apple"} -
Token patterns with one dictionary describing one token (list).
{"label": "GPE", "pattern": [{"LOWER": "san"}, {"LOWER": "francisco"}]}
Using the entity ruler
The EntityRuler is a pipeline component that's typically
added via nlp.add_pipe. When the nlp object is
called on a text, it will find matches in the doc and add them as entities to
the doc.ents, using the specified pattern label as the entity label.
### {executable="true"}
from spacy.lang.en import English
from spacy.pipeline import EntityRuler
nlp = English()
ruler = EntityRuler(nlp)
patterns = [{"label": "ORG", "pattern": "Apple"},
{"label": "GPE", "pattern": [{"LOWER": "san"}, {"LOWER": "francisco"}]}]
ruler.add_patterns(patterns)
nlp.add_pipe(ruler)
doc = nlp("Apple is opening its first big office in San Francisco.")
print([(ent.text, ent.label_) for ent in doc.ents])
The entity ruler is designed to integrate with spaCy's existing statistical
models and enhance the named entity recognizer. If it's added before the
"ner" component, the entity recognizer will respect the existing entity
spans and adjust its predictions around it. This can significantly improve
accuracy in some cases. If it's added after the "ner" component, the
entity ruler will only add spans to the doc.ents if they don't overlap with
existing entities predicted by the model. To overwrite overlapping entities, you
can set overwrite_ents=True on initialization.
### {executable="true"}
import spacy
from spacy.pipeline import EntityRuler
nlp = spacy.load("en_core_web_sm")
ruler = EntityRuler(nlp)
patterns = [{"label": "ORG", "pattern": "MyCorp Inc."}]
ruler.add_patterns(patterns)
nlp.add_pipe(ruler)
doc = nlp("MyCorp Inc. is a company in the U.S.")
print([(ent.text, ent.label_) for ent in doc.ents])
Validating and debugging EntityRuler patterns
The EntityRuler can validate patterns against a JSON schema with the option
validate=True. See details under
Validating and debugging patterns.
ruler = EntityRuler(nlp, validate=True)
Using pattern files
The to_disk and
from_disk let you save and load patterns to and
from JSONL (newline-delimited JSON) files, containing one pattern object per
line.
### patterns.jsonl
{"label": "ORG", "pattern": "Apple"}
{"label": "GPE", "pattern": [{"LOWER": "san"}, {"LOWER": "francisco"}]}
ruler.to_disk("./patterns.jsonl")
new_ruler = EntityRuler(nlp).from_disk("./patterns.jsonl")
If you're using the Prodigy annotation tool, you might
recognize these pattern files from bootstrapping your named entity and text
classification labelling. The patterns for the EntityRuler follow the same
syntax, so you can use your existing Prodigy pattern files in spaCy, and vice
versa.
When you save out an nlp object that has an EntityRuler added to its
pipeline, its patterns are automatically exported to the model directory:
nlp = spacy.load("en_core_web_sm")
ruler = EntityRuler(nlp)
ruler.add_patterns([{"label": "ORG", "pattern": "Apple"}])
nlp.add_pipe(ruler)
nlp.to_disk("/path/to/model")
The saved model now includes the "entity_ruler" in its "pipeline" setting in
the meta.json, and the model directory contains a file entityruler.jsonl
with the patterns. When you load the model back in, all pipeline components will
be restored and deserialized – including the entity ruler. This lets you ship
powerful model packages with binary weights and rules included!
Combining models and rules
You can combine statistical and rule-based components in a variety of ways. Rule-based components can be used to improve the accuracy of statistical models, by presetting tags, entities or sentence boundaries for specific tokens. The statistical models will usually respect these preset annotations, which sometimes improves the accuracy of other decisions. You can also use rule-based components after a statistical model to correct common errors. Finally, rule-based components can reference the attributes set by statistical models, in order to implement more abstract logic.
Example: Expanding named entities
When using the a pretrained named entity recognition model to extract information from your texts, you may find that the predicted span only includes parts of the entity you're looking for. Sometimes, this happens if statistical model predicts entities incorrectly. Other times, it happens if the way the entity type way defined in the original training corpus doesn't match what you need for your application.
Where corpora come from
Corpora used to train models from scratch are often produced in academia. They contain text from various sources with linguistic features labeled manually by human annotators (following a set of specific guidelines). The corpora are then distributed with evaluation data, so other researchers can benchmark their algorithms and everyone can report numbers on the same data. However, most applications need to learn information that isn't contained in any available corpus.
For example, the corpus spaCy's English models were trained on
defines a PERSON entity as just the person name, without titles like "Mr"
or "Dr". This makes sense, because it makes it easier to resolve the entity type
back to a knowledge base. But what if your application needs the full names,
including the titles?
### {executable="true"}
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Dr Alex Smith chaired first board meeting of Acme Corp Inc.")
print([(ent.text, ent.label_) for ent in doc.ents])
While you could try and teach the model a new definition of the PERSON entity
by updating it with more examples of spans
that include the title, this might not be the most efficient approach. The
existing model was trained on over 2 million words, so in order to completely
change the definition of an entity type, you might need a lot of training
examples. However, if you already have the predicted PERSON entities, you can
use a rule-based approach that checks whether they come with a title and if so,
expands the entity span by one token. After all, what all titles in this example
have in common is that if they occur, they occur in the previous token
right before the person entity.
### {highlight="7-11"}
from spacy.tokens import Span
def expand_person_entities(doc):
new_ents = []
for ent in doc.ents:
# Only check for title if it's a person and not the first token
if ent.label_ == "PERSON" and ent.start != 0:
prev_token = doc[ent.start - 1]
if prev_token.text in ("Dr", "Dr.", "Mr", "Mr.", "Ms", "Ms."):
new_ent = Span(doc, ent.start - 1, ent.end, label=ent.label)
new_ents.append(new_ent)
else:
new_ents.append(ent)
doc.ents = new_ents
return doc
The above function takes a Doc object, modifies its doc.ents and returns it.
This is exactly what a pipeline component does,
so in order to let it run automatically when processing a text with the nlp
object, we can use nlp.add_pipe to add it to the
current pipeline.
### {executable="true"}
import spacy
from spacy.tokens import Span
nlp = spacy.load("en_core_web_sm")
def expand_person_entities(doc):
new_ents = []
for ent in doc.ents:
if ent.label_ == "PERSON" and ent.start != 0:
prev_token = doc[ent.start - 1]
if prev_token.text in ("Dr", "Dr.", "Mr", "Mr.", "Ms", "Ms."):
new_ent = Span(doc, ent.start - 1, ent.end, label=ent.label)
new_ents.append(new_ent)
else:
new_ents.append(ent)
doc.ents = new_ents
return doc
# Add the component after the named entity recognizer
nlp.add_pipe(expand_person_entities, after='ner')
doc = nlp("Dr Alex Smith chaired first board meeting of Acme Corp Inc.")
print([(ent.text, ent.label_) for ent in doc.ents])
An alternative approach would be to an
extension attribute
like ._.person_title and add it to Span objects (which includes entity spans
in doc.ents). The advantage here is that the entity text stays intact and can
still be used to look up the name in a knowledge base. The following function
takes a Span object, checks the previous token if it's a PERSON entity and
returns the title if one is found. The Span.doc attribute gives us easy access
to the span's parent document.
def get_person_title(span):
if span.label_ == "PERSON" and span.start != 0:
prev_token = span.doc[span.start - 1]
if prev_token.text in ("Dr", "Dr.", "Mr", "Mr.", "Ms", "Ms."):
return prev_token.text
We can now use the Span.set_extension method to add
the custom extension attribute "person_title", using get_person_title as the
getter function.
### {executable="true"}
import spacy
from spacy.tokens import Span
nlp = spacy.load("en_core_web_sm")
def get_person_title(span):
if span.label_ == "PERSON" and span.start != 0:
prev_token = span.doc[span.start - 1]
if prev_token.text in ("Dr", "Dr.", "Mr", "Mr.", "Ms", "Ms."):
return prev_token.text
# Register the Span extension as 'person_title'
Span.set_extension("person_title", getter=get_person_title)
doc = nlp("Dr Alex Smith chaired first board meeting of Acme Corp Inc.")
print([(ent.text, ent.label_, ent._.person_title) for ent in doc.ents])
Example: Using entities, part-of-speech tags and the dependency parse
Linguistic features
This example makes extensive use of part-of-speech tag and dependency attributes and related
Doc,TokenandSpanmethods. For an introduction on this, see the guide on linguistic features. Also see the annotation specs for details on the label schemes.
Let's say you want to parse professional biographies and extract the person
names and company names, and whether it's a company they're currently working
at, or a previous company. One approach could be to try and train a named
entity recognizer to predict CURRENT_ORG and PREVIOUS_ORG – but this
distinction is very subtle and something the entity recognizer may struggle to
learn. Nothing about "Acme Corp Inc." is inherently "current" or "previous".
However, the syntax of the sentence holds some very important clues: we can check for trigger words like "work", whether they're past tense or present tense, whether company names are attached to it and whether the person is the subject. All of this information is available in the part-of-speech tags and the dependency parse.
### {executable="true"}
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Alex Smith worked at Acme Corp Inc.")
print([(ent.text, ent.label_) for ent in doc.ents])
nsubj: Nominal subject.prep: Preposition.pobj: Object of preposition.NNP: Proper noun, singular.VBD: Verb, past tense.IN: Conjunction, subordinating or preposition.
 visualization with `options={'fine_grained': True}` to output the fine-grained part-of-speech tags, i.e. `Token.tag_`")
In this example, "worked" is the root of the sentence and is a past tense verb.
Its subject is "Alex Smith", the person who worked. "at Acme Corp Inc." is a
prepositional phrase attached to the verb "worked". To extract this
relationship, we can start by looking at the predicted PERSON entities, find
their heads and check whether they're attached to a trigger word like "work".
Next, we can check for prepositional phrases attached to the head and whether
they contain an ORG entity. Finally, to determine whether the company
affiliation is current, we can check the head's part-of-speech tag.
person_entities = [ent for ent in doc.ents if ent.label_ == "PERSON"]
for ent in person_entities:
# Because the entity is a spans, we need to use its root token. The head
# is the syntactic governor of the person, e.g. the verb
head = ent.root.head
if head.lemma_ == "work":
# Check if the children contain a preposition
preps = [token for token in head.children if token.dep_ == "prep"]
for prep in preps:
# Check if tokens part of ORG entities are in the preposition's
# children, e.g. at -> Acme Corp Inc.
orgs = [token for token in prep.children if token.ent_type_ == "ORG"]
# If the verb is in past tense, the company was a previous company
print({'person': ent, 'orgs': orgs, 'past': head.tag_ == "VBD"})
To apply this logic automatically when we process a text, we can add it to the
nlp object as a
custom pipeline component. The
above logic also expects that entities are merged into single tokens. spaCy
ships with a handy built-in merge_entities that takes care of that. Instead of
just printing the result, you could also write it to
custom attributes on
the entity Span – for example ._.orgs or ._.prev_orgs and
._.current_orgs.
Merging entities
Under the hood, entities are merged using the
Doc.retokenizecontext manager:with doc.retokenize() as retokenize: for ent in doc.ents: retokenizer.merge(ent)
### {executable="true"}
import spacy
from spacy.pipeline import merge_entities
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
def extract_person_orgs(doc):
person_entities = [ent for ent in doc.ents if ent.label_ == "PERSON"]
for ent in person_entities:
head = ent.root.head
if head.lemma_ == "work":
preps = [token for token in head.children if token.dep_ == "prep"]
for prep in preps:
orgs = [token for token in prep.children if token.ent_type_ == "ORG"]
print({'person': ent, 'orgs': orgs, 'past': head.tag_ == "VBD"})
return doc
# To make the entities easier to work with, we'll merge them into single tokens
nlp.add_pipe(merge_entities)
nlp.add_pipe(extract_person_orgs)
doc = nlp("Alex Smith worked at Acme Corp Inc.")
# If you're not in a Jupyter / IPython environment, use displacy.serve
displacy.render(doc, options={'fine_grained': True})
If you change the sentence structure above, for example to "was working", you'll notice that our current logic fails and doesn't correctly detect the company as a past organization. That's because the root is a participle and the tense information is in the attached auxiliary "was":

To solve this, we can adjust the rules to also check for the above construction:
### {highlight="9-11"}
def extract_person_orgs(doc):
person_entities = [ent for ent in doc.ents if ent.label_ == "PERSON"]
for ent in person_entities:
head = ent.root.head
if head.lemma_ == "work":
preps = [token for token in head.children if token.dep_ == "prep"]
for prep in preps:
orgs = [t for t in prep.children if t.ent_type_ == "ORG"]
aux = [token for token in head.children if token.dep_ == "aux"]
past_aux = any(t.tag_ == "VBD" for t in aux)
past = head.tag_ == "VBD" or head.tag_ == "VBG" and past_aux
print({'person': ent, 'orgs': orgs, 'past': past})
return doc
In your final rule-based system, you may end up with several different code paths to cover the types of constructions that occur in your data.