mirror of https://github.com/google/oss-fuzz.git
35 lines
1.8 KiB
Markdown
35 lines
1.8 KiB
Markdown
# Accessing Corpora
|
|
|
|
If you would like to access the corpora that we are using for your fuzz targets (synthesized by the fuzzing engines), please follow these steps.
|
|
|
|
## Install Google Cloud SDK
|
|
|
|
The corpora for fuzz targets are stored on [Google Cloud Storage](https://cloud.google.com/storage/). To access them, you will need to [install](https://cloud.google.com/storage/docs/gsutil_install) the gsutil tool, which is part of the Google Cloud SDK.
|
|
Follow the instructions on the installation page to login with a Google account listed in your project's `project.yaml` file.
|
|
|
|
## Viewing the corpus for a fuzz target
|
|
|
|
The fuzzer statistics page for your project on [ClusterFuzz](clusterfuzz.md) will contain a link to the Google Cloud console for your corpus under the "corpus_size" column. You can browse and download individual test inputs in the corpus here.
|
|
|
|

|
|
|
|
## Downloading the corpus
|
|
|
|
If you would like to download the entire corpus, from the cloud console link, copy the bucket path highlighted here:
|
|
|
|
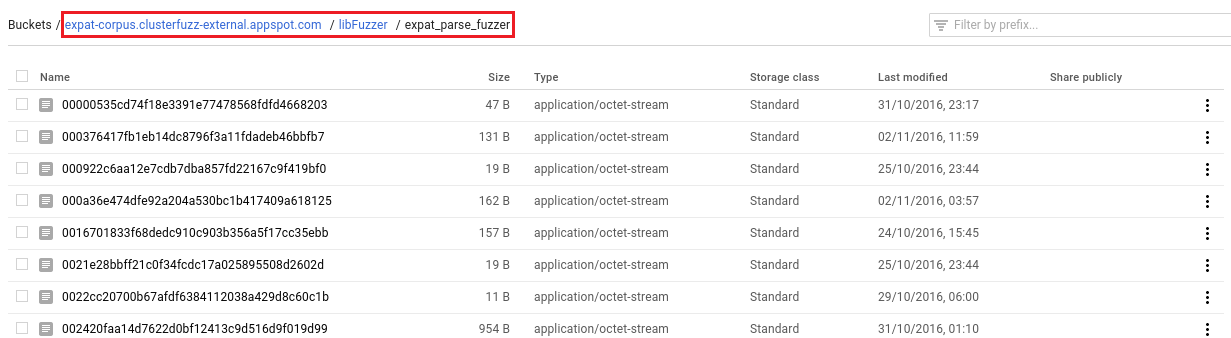
|
|
|
|
And then run the following command to copy the corpus to a directory on your machine.
|
|
|
|
```bash
|
|
gsutil -m rsync gs://<bucket_path> <local_directory>
|
|
```
|
|
Following the expat example above, this would be:
|
|
|
|
```bash
|
|
gsutil -m rsync gs://expat-corpus.clusterfuzz-external.appspot.com/libFuzzer/expat_parse_fuzzer <local_directory>
|
|
```
|
|
## Corpus backups
|
|
|
|
We also keep daily zipped backups of your corpora. These can be accessed from the `corpus_backup` column of the fuzzer statistics page. Downloading these can also be significantly faster than `gsutil -m rsync` on the corpus bucket.
|