21 KiB
![]()
PyTorch Lightning
The lightweight PyTorch wrapper for ML researchers. Scale your models. Write less boilerplate.
![]()


![]()
![]()
![]()
Simple installation from PyPI
pip install pytorch-lightning
Docs
What is it?
Lightning is a very lightweight wrapper on PyTorch. This means you don't have to learn a new library. To use Lightning, simply refactor your research code into the LightningModule format and Lightning will automate the rest. Lightning guarantees tested, correct, modern best practices for the automated parts.
How much effort is it to convert?
You're probably tired of switching frameworks at this point. But it is a very quick process to refactor into the Lightning format. Check out this tutorial
Starting a new project?
Use our seed-project aimed at reproducibility!
Why do I want to use lightning?
Every research project starts the same, a model, a training loop, validation loop, etc. As your research advances, you're likely to need distributed training, 16-bit precision, checkpointing, gradient accumulation, etc.
Lightning sets up all the boilerplate state-of-the-art training for you so you can focus on the research.
README Table of Contents
- How do I use it
- What lightning automates
- Tensorboard integration
- Lightning features
- Examples
- Tutorials
- Contributing
- Bleeding edge install
- Lightning Design Principles
- Asking for help
- FAQ
How do I do use it?
Think about Lightning as refactoring your research code instead of using a new framework. The research code goes into a LightningModule which you fit using a Trainer.
The LightningModule defines a system such as seq-2-seq, GAN, etc... It can ALSO define a simple classifier such as the example below.
To use lightning do 2 things:
- Define a LightningModule
WARNING: This syntax is for version 0.5.0+ where abbreviations were removed.
import os import torch from torch.nn import functional as F from torch.utils.data import DataLoader from torchvision.datasets import MNIST from torchvision import transforms import pytorch_lightning as pl class CoolSystem(pl.LightningModule): def __init__(self): super(CoolSystem, self).__init__() # not the best model... self.l1 = torch.nn.Linear(28 * 28, 10) def forward(self, x): return torch.relu(self.l1(x.view(x.size(0), -1))) def training_step(self, batch, batch_idx): # REQUIRED x, y = batch y_hat = self.forward(x) loss = F.cross_entropy(y_hat, y) tensorboard_logs = {'train_loss': loss} return {'loss': loss, 'log': tensorboard_logs} def validation_step(self, batch, batch_idx): # OPTIONAL x, y = batch y_hat = self.forward(x) return {'val_loss': F.cross_entropy(y_hat, y)} def validation_end(self, outputs): # OPTIONAL avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean() tensorboard_logs = {'val_loss': avg_loss} return {'avg_val_loss': avg_loss, 'log': tensorboard_logs} def configure_optimizers(self): # REQUIRED # can return multiple optimizers and learning_rate schedulers # (LBFGS it is automatically supported, no need for closure function) return torch.optim.Adam(self.parameters(), lr=0.02) @pl.data_loader def train_dataloader(self): # REQUIRED return DataLoader(MNIST(os.getcwd(), train=True, download=True, transform=transforms.ToTensor()), batch_size=32) @pl.data_loader def val_dataloader(self): # OPTIONAL return DataLoader(MNIST(os.getcwd(), train=True, download=True, transform=transforms.ToTensor()), batch_size=32) @pl.data_loader def test_dataloader(self): # OPTIONAL return DataLoader(MNIST(os.getcwd(), train=False, download=True, transform=transforms.ToTensor()), batch_size=32) - Fit with a trainer
from pytorch_lightning import Trainer model = CoolSystem() # most basic trainer, uses good defaults trainer = Trainer() trainer.fit(model)
Trainer sets up a tensorboard logger, early stopping and checkpointing by default (you can modify all of them or use something other than tensorboard).
Here are more advanced examples
# train on cpu using only 10% of the data (for demo purposes)
trainer = Trainer(max_num_epochs=1, train_percent_check=0.1)
# train on 4 gpus (lightning chooses GPUs for you)
# trainer = Trainer(max_num_epochs=1, gpus=4, distributed_backend='ddp')
# train on 4 gpus (you choose GPUs)
# trainer = Trainer(max_num_epochs=1, gpus=[0, 1, 3, 7], distributed_backend='ddp')
# train on 32 gpus across 4 nodes (make sure to submit appropriate SLURM job)
# trainer = Trainer(max_num_epochs=1, gpus=8, num_gpu_nodes=4, distributed_backend='ddp')
# train (1 epoch only here for demo)
trainer.fit(model)
# view tensorboard logs
logging.info(f'View tensorboard logs by running\ntensorboard --logdir {os.getcwd()}')
logging.info('and going to http://localhost:6006 on your browser')
When you're all done you can even run the test set separately.
trainer.test()
What does lightning control for me?
Everything in gray!
You define the blue parts using the LightningModule interface:
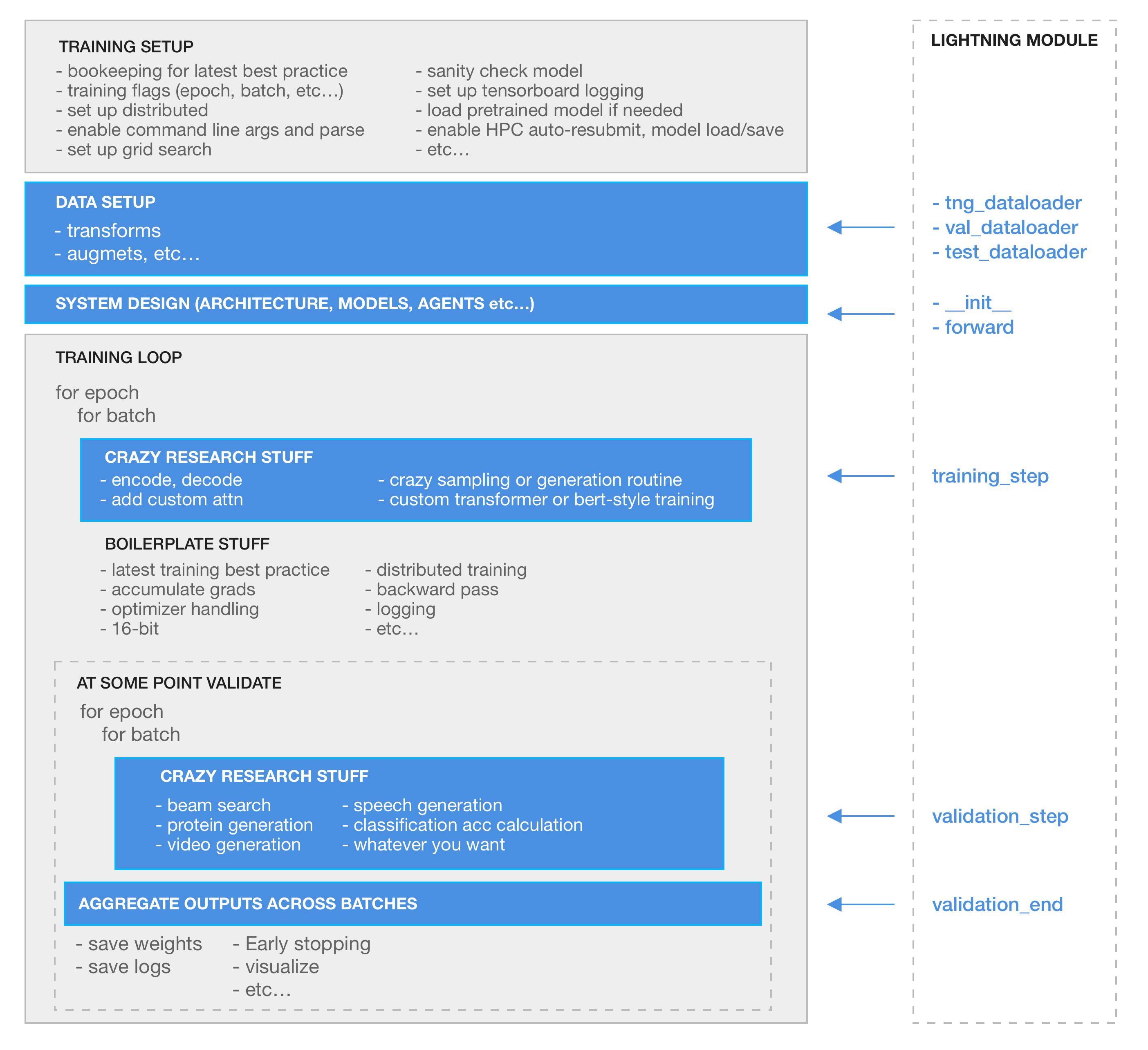
# what to do in the training loop
def training_step(self, batch, batch_idx):
# what to do in the validation loop
def validation_step(self, batch, batch_idx):
# how to aggregate validation_step outputs
def validation_end(self, outputs):
# and your dataloaders
def train_dataloader():
def val_dataloader():
def test_dataloader():
Could be as complex as seq-2-seq + attention
# define what happens for training here
def training_step(self, batch, batch_idx):
x, y = batch
# define your own forward and loss calculation
hidden_states = self.encoder(x)
# even as complex as a seq-2-seq + attn model
# (this is just a toy, non-working example to illustrate)
start_token = '<SOS>'
last_hidden = torch.zeros(...)
loss = 0
for step in range(max_seq_len):
attn_context = self.attention_nn(hidden_states, start_token)
pred = self.decoder(start_token, attn_context, last_hidden)
last_hidden = pred
pred = self.predict_nn(pred)
loss += self.loss(last_hidden, y[step])
#toy example as well
loss = loss / max_seq_len
return {'loss': loss}
Or as basic as CNN image classification
# define what happens for validation here
def validation_step(self, batch, batch_idx):
x, y = batch
# or as basic as a CNN classification
out = self.forward(x)
loss = my_loss(out, y)
return {'loss': loss}
And you also decide how to collate the output of all validation steps
def validation_end(self, outputs):
"""
Called at the end of validation to aggregate outputs
:param outputs: list of individual outputs of each validation step
:return:
"""
val_loss_mean = 0
val_acc_mean = 0
for output in outputs:
val_loss_mean += output['val_loss']
val_acc_mean += output['val_acc']
val_loss_mean /= len(outputs)
val_acc_mean /= len(outputs)
logs = {'val_loss': val_loss_mean.item(), 'val_acc': val_acc_mean.item()}
result = {'log': logs}
return result
Tensorboard
Lightning is fully integrated with tensorboard, MLFlow and supports any logging module.
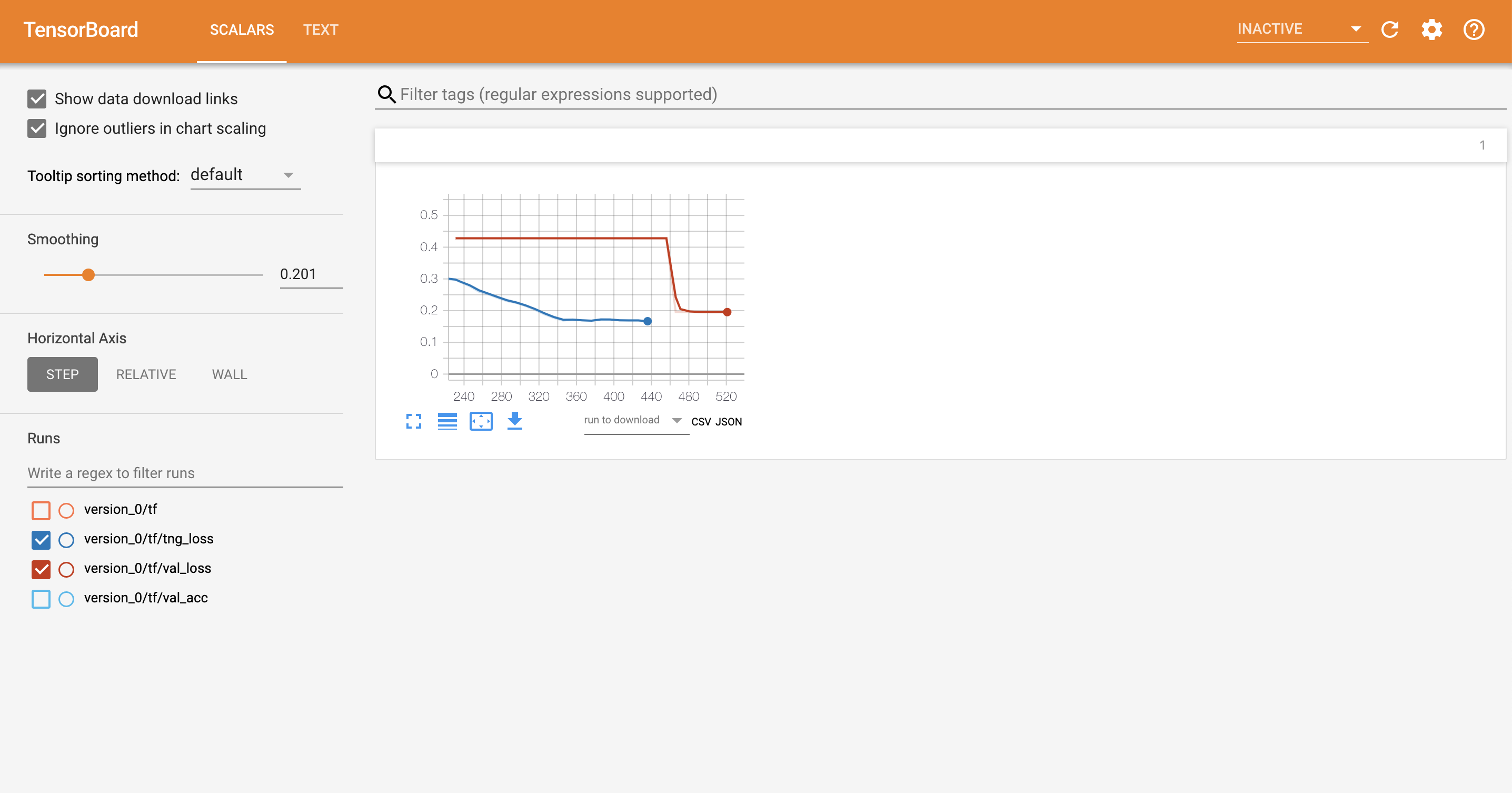
Lightning also adds a text column with all the hyperparameters for this experiment.

Lightning automates all of the following (each is also configurable):
Checkpointing
Computing cluster (SLURM)
Debugging
- Fast dev run
- Inspect gradient norms
- Log GPU usage
- Make model overfit on subset of data
- Print the parameter count by layer
- Print which gradients are nan
- Print input and output size of every module in system
Distributed training
- Implement Your Own Distributed (DDP) training
- 16-bit mixed precision
- Multi-GPU
- Multi-node
- Single GPU
- Self-balancing architecture
Experiment Logging
- Display metrics in progress bar
- Log metric row every k batches
- Process position
- Tensorboard support
- Save a snapshot of all hyperparameters
- Snapshot code for a training run
- Write logs file to csv every k batches
Training loop
- Accumulate gradients
- Force training for min or max epochs
- Early stopping callback
- Force disable early stop
- Gradient Clipping
- Hooks
- Learning rate scheduling
- Use multiple optimizers (like GANs)
- Set how much of the training set to check (1-100%)
- Step optimizers at arbitrary intervals
Validation loop
- Check validation every n epochs
- Hooks
- Set how much of the validation set to check
- Set how much of the test set to check
- Set validation check frequency within 1 training epoch
- Set the number of validation sanity steps
Testing loop
Examples
Tutorials
- Basic Lightning use
- 9 key speed features in Pytorch-Lightning
- SLURM, multi-node training with Lightning
Asking for help
Welcome to the Lightning community!
If you have any questions, feel free to:
- read the docs.
- Search through the issues.
- Ask on stackoverflow with the tag pytorch-lightning.
If no one replies to you quickly enough, feel free to post the stackoverflow link to our Gitter chat!
To chat with the rest of us visit our gitter channel!
FAQ
How do I use Lightning for rapid research?
Here's a walk-through
Why was Lightning created?
Lightning has 3 goals in mind:
- Maximal flexibility while abstracting out the common boilerplate across research projects.
- Reproducibility. If all projects use the LightningModule template, it will be much much easier to understand what's going on and where to look! It will also mean every implementation follows a standard format.
- Democratizing PyTorch power user features. Distributed training? 16-bit? know you need them but don't want to take the time to implement? All good... these come built into Lightning.
How does Lightning compare with Ignite and fast.ai?
Here's a thorough comparison.
Is this another library I have to learn?
Nope! We use pure Pytorch everywhere and don't add unecessary abstractions!
Are there plans to support Python 2?
Nope.
Are there plans to support virtualenv?
Nope. Please use anaconda or miniconda.
Which PyTorch versions do you support?
- PyTorch 1.1.0
# install pytorch 1.1.0 using the official instructions # install test-tube 0.6.7.6 which supports 1.1.0 pip install test-tube==0.6.7.6 # install latest Lightning version without upgrading deps pip install -U --no-deps pytorch-lightning - PyTorch 1.2.0, 1.3.0, Install via pip as normal
Custom installation
Bleeding edge
If you can't wait for the next release, install the most up to date code with:
- using GIT (locally clone whole repo with full history)
pip install git+https://github.com/williamFalcon/pytorch-lightning.git@master --upgrade - using instant zip (last state of the repo without git history)
pip install https://github.com/williamFalcon/pytorch-lightning/archive/master.zip --upgrade
Any release installation
You can also install any past release from this repository:
pip install https://github.com/williamFalcon/pytorch-lightning/archive/0.4.4.zip --upgrade
Bibtex
If you want to cite the framework feel free to use this (but only if you loved it 😊):
@misc{Falcon2019,
author = {Falcon, W.A.},
title = {PyTorch Lightning},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/williamFalcon/pytorch-lightning}}
}