* added custom mnist without torchvision dep * move files so it does not conflict with mnist gitignore * mock torchvision for tests * fix line too long * fix line too long * fix "module level import not at top of file" warning * move mock imports to __init__.py * simplify MNIST a lot and download directly the .pt files * further simplify and clean up mnist * revert import overrides * make as before * drop PIL requirement * move mnist.py to datasets subfolder * use logging instead of print * choose same name as in torchvision * remove torchvision and pillow also from yml file * refactor if train Co-Authored-By: Jirka Borovec <Borda@users.noreply.github.com> * capitalized class attr * moved mnist to models * re-added datsets ignore * better name for file variable * Update mnist.py * move dataset classes to datasets.py * new line * update * update * fix automerge * move to base folder * adapt testingmnist to new mnist base class * remove temporal fix * fix datatype * remove old testingmnist * readable * fix import * fix whitespace * docstring Co-Authored-By: Jirka Borovec <Borda@users.noreply.github.com> * Update tests/base/datasets.py Co-Authored-By: Jirka Borovec <Borda@users.noreply.github.com> * changelog * added types * Update CHANGELOG.md Co-Authored-By: Jirka Borovec <Borda@users.noreply.github.com> * exist->isfile Co-Authored-By: Jirka Borovec <Borda@users.noreply.github.com> * index -> idx * temporary fix for trains error * better changelog message Co-authored-by: Jirka Borovec <Borda@users.noreply.github.com> |
||
|---|---|---|
| .circleci | ||
| .github | ||
| benchmarks | ||
| docs | ||
| pl_examples | ||
| pytorch_lightning | ||
| tests | ||
| .codecov.yml | ||
| .drone.yml | ||
| .gitignore | ||
| .mergify.yml | ||
| .pep8speaks.yml | ||
| .readthedocs.yml | ||
| .run_local_tests.sh | ||
| CHANGELOG.md | ||
| LICENSE | ||
| MANIFEST.in | ||
| README.md | ||
| environment.yml | ||
| pyproject.toml | ||
| requirements-extra.txt | ||
| requirements.txt | ||
| setup.cfg | ||
| setup.py | ||
| update.sh | ||
README.md
![]()
PyTorch Lightning
The lightweight PyTorch wrapper for ML researchers. Scale your models. Write less boilerplate.
![]()
![]()
![]()
![]()
![]()
Continuous Integration
| System / PyTorch ver. | 1.1 | 1.2 | 1.3 | 1.4 |
|---|---|---|---|---|
| Linux py3.6 [CPU] |  |
|
|
|
| Linux py3.7 [GPU] | — | — | — |  |
| Linux py3.6 / py3.7 | — | — | ||
| OSX py3.6 / py3.7 | — | — | ||
| Windows py3.6 / py3.7 | — | — |
Simple installation from PyPI
pip install pytorch-lightning
Docs
Demo
MNIST, GAN, BERT on COLAB! MNIST on TPUs
What is it?
Lightning is a way to organize your PyTorch code to decouple the science code from the engineering. It's more of a style-guide than a framework.
To use Lightning, first refactor your research code into a LightningModule.

And Lightning automates the rest using the Trainer!
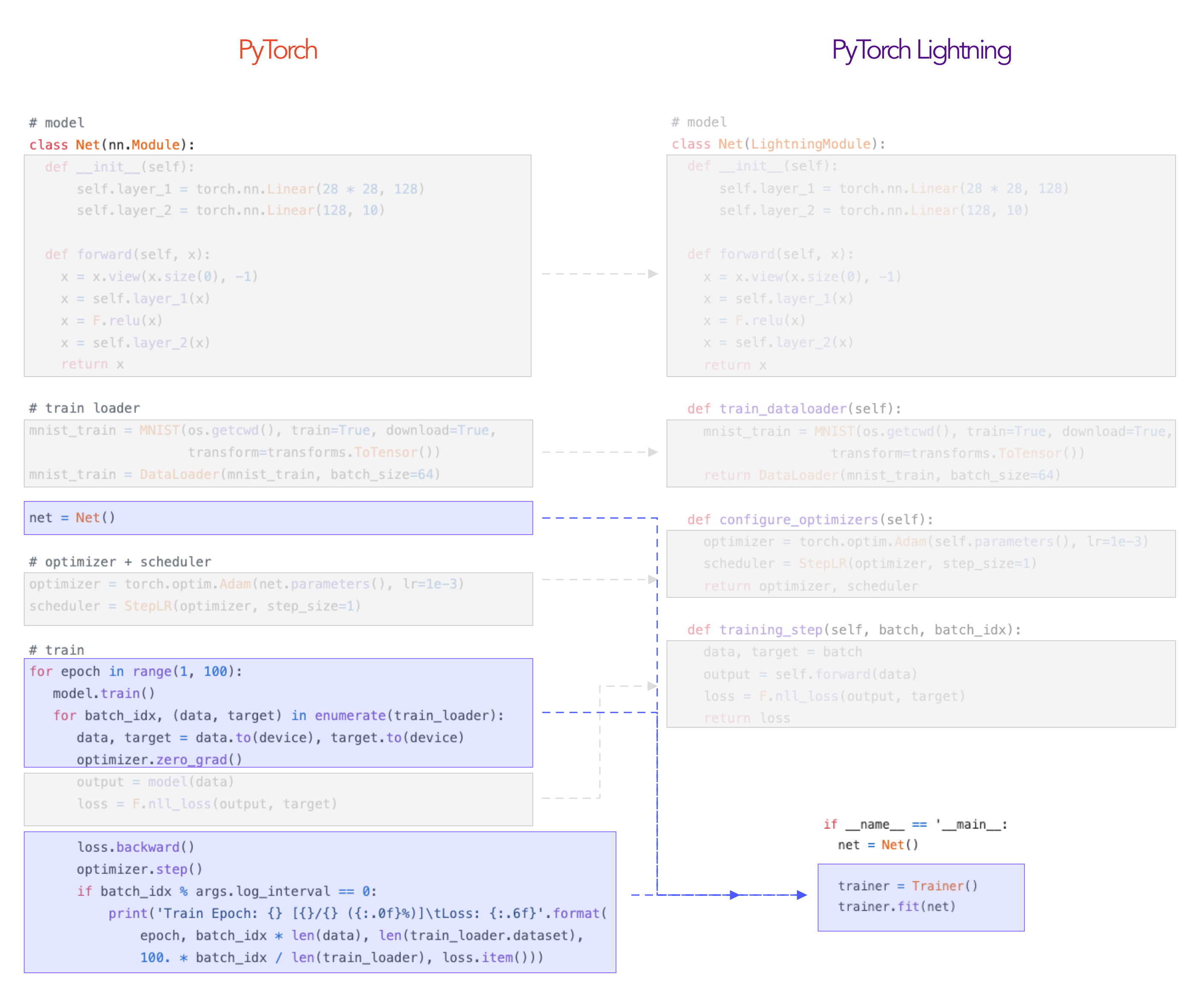
Lightning guarantees rigorously tested, correct, modern best practices for the automated parts.
How flexible is it?
As you see, you're just organizing your PyTorch code - there's no abstraction.
And for the stuff that the Trainer abstracts out you can override any part you want to do things like implement your own distributed training, 16-bit precision, or even a custom backwards pass.
For anything else you might need, we have an extensive callback system you can use to add arbitrary functionality not implemented by our team in the Trainer.
Who is Lightning for?
- Professional researchers
- PhD students
- Corporate production teams
If you're just getting into deep learning, we recommend you learn PyTorch first! Once you've implemented a few models, come back and use all the advanced features of Lightning :)
What does lightning control for me?
Everything in Blue! This is how lightning separates the science (red) from the engineering (blue).

How much effort is it to convert?
If your code is not a huge mess you should be able to organize it into a LightningModule in less than 1 hour. If your code IS a mess, then you needed to clean up anyhow ;)
Check out this step-by-step guide.
Starting a new project?
Use our seed-project aimed at reproducibility!
Why do I want to use lightning?
Although your research/production project might start simple, once you add things like GPU AND TPU training, 16-bit precision, etc, you end up spending more time engineering than researching. Lightning automates AND rigorously tests those parts for you.
Support
- 8 core contributors who are all a mix of professional engineers, Research Scientists, PhD students from top AI labs.
- 100+ community contributors.
Lightning is also part of the PyTorch ecosystem which requires projects to have solid testing, documentation and support.
README Table of Contents
- How do I use it
- What lightning automates
- Tensorboard integration
- Lightning features
- Examples
- Tutorials
- Asking for help
- Contributing
- Bleeding edge install
- Lightning Design Principles
- Lightning team
- FAQ
Realistic example
Here's how you would organize a realistic PyTorch project into Lightning.
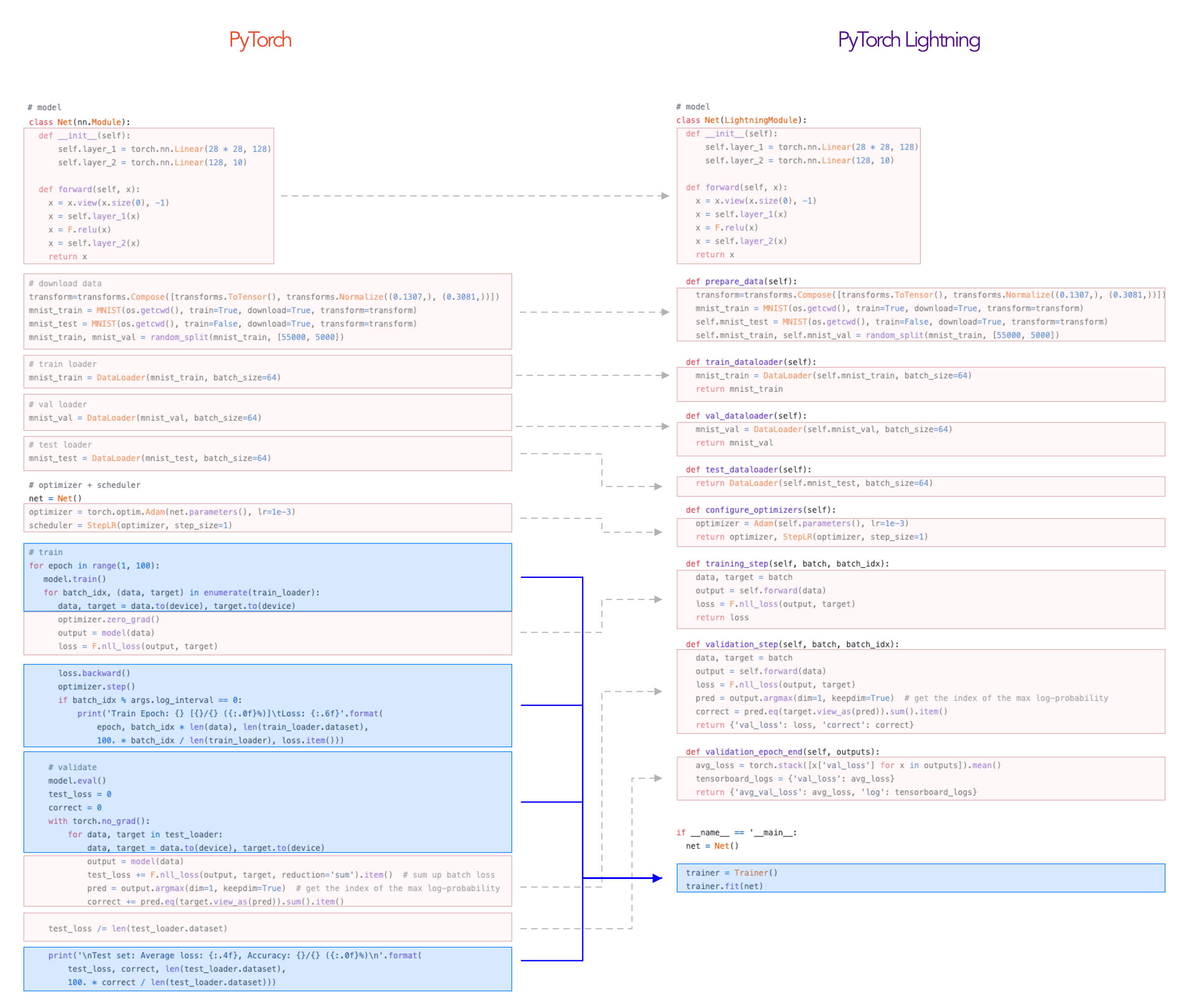
The LightningModule defines a system such as seq-2-seq, GAN, etc... It can ALSO define a simple classifier.
In summary, you:
- Define a LightningModule
class LitSystem(pl.LightningModule):
def __init__(self):
super().__init__()
# not the best model...
self.l1 = torch.nn.Linear(28 * 28, 10)
def forward(self, x):
return torch.relu(self.l1(x.view(x.size(0), -1)))
def training_step(self, batch, batch_idx):
...
- Fit it with a Trainer
from pytorch_lightning import Trainer
model = LitSystem()
# most basic trainer, uses good defaults
trainer = Trainer()
trainer.fit(model)
What types of research works?
Anything! Remember, that this is just organized PyTorch code. The Training step defines the core complexity found in the training loop.
Could be as complex as a seq2seq
# define what happens for training here
def training_step(self, batch, batch_idx):
x, y = batch
# define your own forward and loss calculation
hidden_states = self.encoder(x)
# even as complex as a seq-2-seq + attn model
# (this is just a toy, non-working example to illustrate)
start_token = '<SOS>'
last_hidden = torch.zeros(...)
loss = 0
for step in range(max_seq_len):
attn_context = self.attention_nn(hidden_states, start_token)
pred = self.decoder(start_token, attn_context, last_hidden)
last_hidden = pred
pred = self.predict_nn(pred)
loss += self.loss(last_hidden, y[step])
#toy example as well
loss = loss / max_seq_len
return {'loss': loss}
Or as basic as CNN image classification
# define what happens for validation here
def validation_step(self, batch, batch_idx):
x, y = batch
# or as basic as a CNN classification
out = self(x)
loss = my_loss(out, y)
return {'loss': loss}
And without changing a single line of code, you could run on CPUs
trainer = Trainer(max_epochs=1)
Or GPUs
# 8 GPUs
trainer = Trainer(max_epochs=1, gpus=8)
# 256 GPUs
trainer = Trainer(max_epochs=1, gpus=8, num_nodes=32)
Or TPUs
trainer = Trainer(num_tpu_cores=8)
When you're done training, run the test accuracy
trainer.test()
Visualization
Lightning has out-of-the-box integration with the popular logging/visualizing frameworks
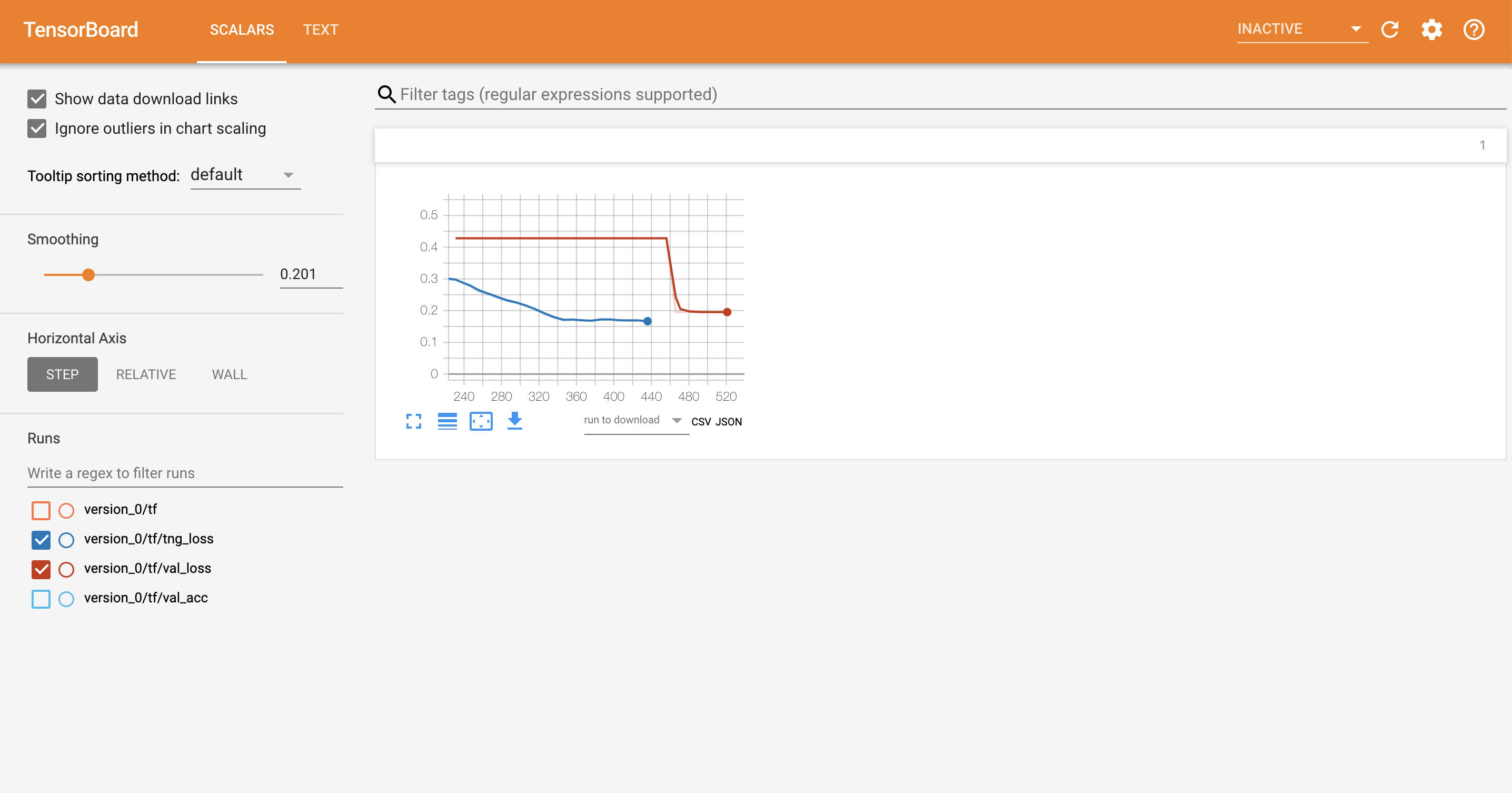
Lightning automates 40+ parts of DL/ML research
- GPU training
- Distributed GPU (cluster) training
- TPU training
- EarlyStopping
- Logging/Visualizing
- Checkpointing
- Experiment management
- Full list here
Examples
Check out this awesome list of research papers and implementations done with Lightning.
- Contextual Emotion Detection (DoubleDistilBert)
- Generative Adversarial Network
- Hyperparameter optimization with Optuna
- Image Inpainting using Partial Convolutions
- MNIST on TPU
- NER (transformers, TPU, huggingface)
- NeuralTexture (CVPR)
- Recurrent Attentive Neural Process
- Siamese Nets for One-shot Image Recognition
- Speech Transformers
- Transformers transfer learning (Huggingface)
- Transformers text classification
- VAE Library of over 18+ VAE flavors
Tutorials
Check out our introduction guide to get started. Or jump straight into our tutorials.
Asking for help
Welcome to the Lightning community!
If you have any questions, feel free to:
- read the docs.
- Search through the issues.
- Ask on stackoverflow with the tag pytorch-lightning.
- Join our slack.
FAQ
How do I use Lightning for rapid research? Here's a walk-through
Why was Lightning created? Lightning has 3 goals in mind:
- Maximal flexibility while abstracting out the common boilerplate across research projects.
- Reproducibility. If all projects use the LightningModule template, it will be much much easier to understand what's going on and where to look! It will also mean every implementation follows a standard format.
- Democratizing PyTorch power user features. Distributed training? 16-bit? know you need them but don't want to take the time to implement? All good... these come built into Lightning.
How does Lightning compare with Ignite and fast.ai? Here's a thorough comparison.
Is this another library I have to learn? Nope! We use pure Pytorch everywhere and don't add unnecessary abstractions!
Are there plans to support Python 2? Nope.
Are there plans to support virtualenv? Nope. Please use anaconda or miniconda.
Which PyTorch versions do you support?
- PyTorch 1.1.0
# install pytorch 1.1.0 using the official instructions # install test-tube 0.6.7.6 which supports 1.1.0 pip install test-tube==0.6.7.6 # install latest Lightning version without upgrading deps pip install -U --no-deps pytorch-lightning - PyTorch 1.2.0, 1.3.0, Install via pip as normal
Custom installation
Bleeding edge
If you can't wait for the next release, install the most up to date code with:
- using GIT (locally clone whole repo with full history)
pip install git+https://github.com/PytorchLightning/pytorch-lightning.git@master --upgrade - using instant zip (last state of the repo without git history)
pip install https://github.com/PytorchLightning/pytorch-lightning/archive/master.zip --upgrade
Any release installation
You can also install any past release 0.X.Y from this repository:
pip install https://github.com/PytorchLightning/pytorch-lightning/archive/0.X.Y.zip --upgrade
Lightning team
Leads
- William Falcon (williamFalcon) (Lightning founder)
- Jirka Borovec (Borda) (ghost :)
- Ethan Harris (ethanwharris) (Torchbearer founder)
- Matthew Painter (MattPainter01) (Torchbearer founder)
- Justus Schock (justusschock) (Former Core Member PyTorch Ignite)
Core Maintainers
- Nick Eggert (neggert)
- Jeff Ling (jeffling)
- Jeremy Jordan (jeremyjordan)
- Tullie Murrell (tullie)
Bibtex
If you want to cite the framework feel free to use this (but only if you loved it 😊):
@misc{Falcon2019,
author = {Falcon, W.A. et al.},
title = {PyTorch Lightning},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/PytorchLightning/pytorch-lightning}}
}