# Proximal Policy Optimization - PPO implementation powered by Lightning Fabric
This is an example of a Reinforcement Learning algorithm called [Proximal Policy Optimization (PPO)](https://arxiv.org/abs/1707.06347) implemented in PyTorch and accelerated by [Lightning Fabric](https://lightning.ai/docs/fabric).
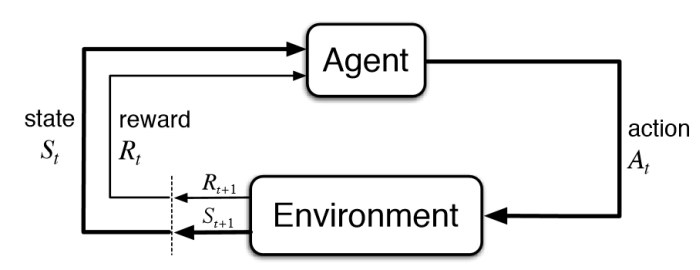
The goal of Reinforcement Learning is to train agents to act in their surrounding environment maximizing the cumulative reward received from it. This can be depicted in the following figure:
PPO is one of such algorithms, which alternates between sampling data through interaction with the environment, and optimizing a
“surrogate” objective function using stochastic gradient ascent.
## Requirements
Install requirements by running
```bash
pip install -r requirements.txt
```
## Example 1 - Environment coupled with the agent
In this example we present two code versions: the first one is implemented in raw PyTorch, but it contains quite a bit of boilerplate code for distributed training. The second one is using Lightning Fabric to accelerate and scale the model.
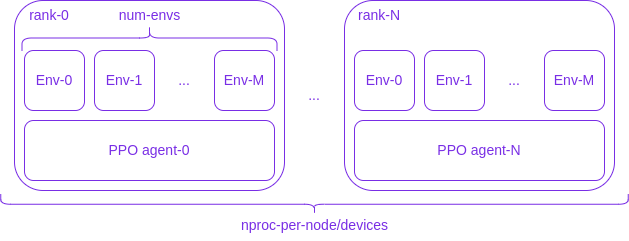
The main architecture is the following:
where `N+1` processes (labelled *rank-0*, ..., *rank-N* in the figure above) will be spawned by Fabric/PyTorch, each of them running `M+1` independent copies of the environment (*Env-0*, ..., *Env-M*). Every rank has its own copy of the agent, represented by a [LightningModule](https://lightning.ai/docs/pytorch/stable/common/lightning_module.html)/[Pytorch Module](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), which will be updated through distributed training.
### Raw PyTorch:
```bash
torchrun --nproc_per_node=2 --standalone train_torch.py
```
### Lightning Fabric:
```bash
lightning run model --accelerator=cpu --strategy=ddp --devices=2 train_fabric.py
```
### Visualizing logs
You can visualize training and test logs by running:
```bash
tensorboard --logdir logs
```
Under the `logs` folder you should find two folders:
- `logs/torch_logs`
- `logs/fabric_logs`
If you have run the experiment with the `--capture-video` you should find the `train_videos` and `test_videos` folders under the specific experiment folder.
## Results
The following video shows a trained agent on the [LunarLander-v2 environment](https://gymnasium.farama.org/environments/box2d/lunar_lander/).
The agent was trained with the following:
```bash
lightning run model \
--accelerator=cpu \
--strategy=ddp \
--devices=2 \
train_fabric.py \
--capture-video \
--env-id LunarLander-v2 \
--total-timesteps 500000 \
--ortho-init \
--num-envs 2 \
--num-steps 2048 \
--seed 1
```
## Example 2 - Environment decoupled from the agent
In this example we have gone even further leveraging the flexibility offered by [Fabric](https://lightning.ai/docs/fabric).
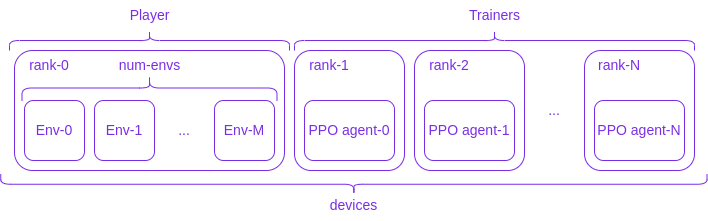
The architecture is depicted in the following figure:
where, differently from the previous example, we have completely decoupled the environment from the agents: the *rank-0* process will be regarded as the *Player*, which runs `M+1` independent copies of the environment (*Env-0*, ..., *Env-M*); the *rank-1*, ..., *rank-N* are the *Trainers*, which contain the agent to be optimized. Player and Trainer share data through [collectives](https://lightning.ai/docs/fabric/stable/api/generated/lightning.fabric.plugins.collectives.TorchCollective.html#lightning.fabric.plugins.collectives.TorchCollective) and thanks to Fabric's flexibility we can run Player and Trainers on different devices.
So for example:
```bash
lightning run model --devices=3 train_fabric_decoupled.py --num-envs 4
```
will spawn 3 processes, one is the Player and the others the Trainers, with the Player running 4 independent environments, where every process runs on the CPU;
```bash
lightning run model --devices=3 train_fabric_decoupled.py --num-envs 4 --cuda
```
will instead run only the Trainers on the GPU.
If one wants to run both the Player and the Trainers on the GPU, then both the flags `--cuda` and `--player-on-gpu` must be provided:
```bash
lightning run model --devices=3 train_fabric_decoupled.py --num-envs 4 --cuda --player-on-gpu
```
> **Warning**
>
> With this second example, there is no need for the user to provide the `accellerator` and the `strategy` to the `lightning run model` script.
## Number of updates, environment steps and share data
In every one of the examples above, one has that:
- The number of total updates will be given by `args.total_timesteps / args.num_steps`
- `args.num_steps` is the number of environment interactions before the agent training step, i.e. the agent gathers `args.num_steps` experiences and uses them to update itself during the training step
- `args.share_data` controls how the data is shared between processes. In particular:
- In the first example, **if `args.share_data` is set** then every process will have access at the data gathered by all the other processes, effectively calling the [all_gather](https://pytorch.org/docs/stable/distributed.html#torch.distributed.all_gather) distributed function. In this way, during the training step, the agents can employ the standard [PyTorch distributed training receipe](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html#torch.nn.parallel.DistributedDataParallel), where one can assume that before the training starts every process sees the same data, and trains the model on a disjoint subset (from process to process) of it. Otherwise, **if `args.share_data` is not set** (the default), then every process will update the model with its own local data
- In the second example, when **`args.share_data` is set** then one has the same behaviour of the first example. Instead, when **`args.share_data` is not set** then the player scatters an almost-equal-sized subset of the collected experiences to the trainers, effectively calling the [scatter](https://pytorch.org/docs/stable/distributed.html#torch.distributed.scatter) distributed function