how the hydrus network synchronises
The hydrus network does not work like regular client-server architectures.
The most important difference is its decentralisation of processing; rather than make an expensive http request every time it wants something, the client makes an all-inclusive synchronisation request about once a day and performs all searches on its local cache.
so, how does the client make sure it has what it needs to do its searches?
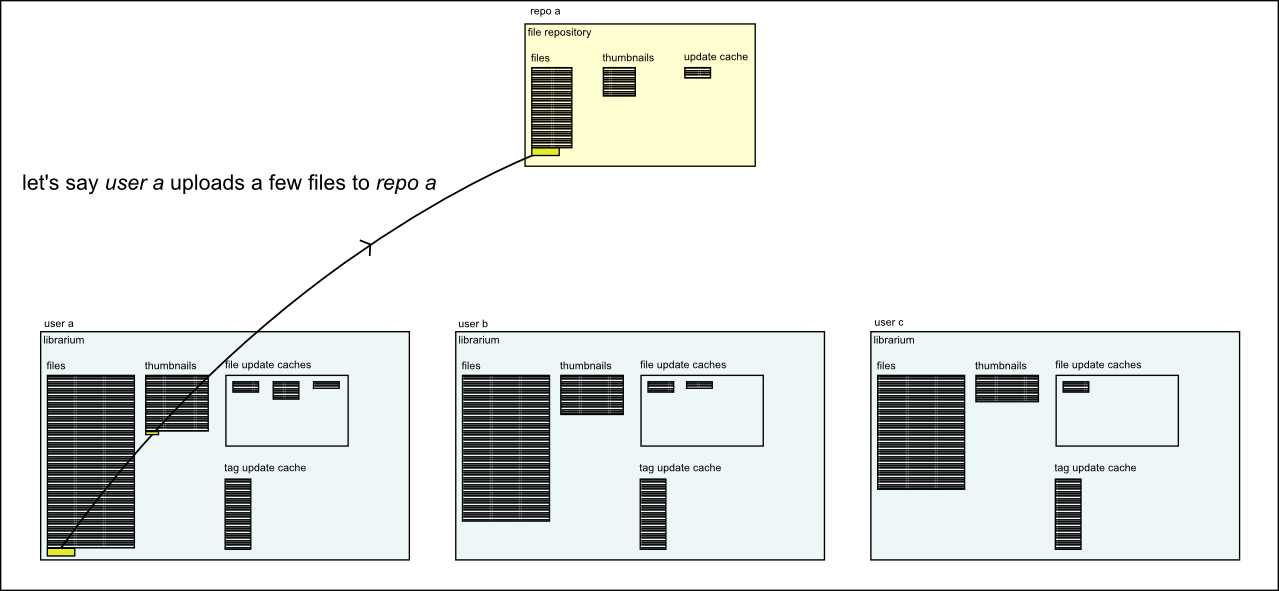
When the client contacts a repository, it downloads every single change that has occured since the last time it checked. It keeps all this data, and searches over whatever is appropriate to its own circumstances. If its local circumstances change (e.g. you import a thousand new files), it doesn't need to download anything more. A repository does not know anything about any particular client's circumstances.
tell me more! use diagrams!
These diagrams are a little old! 'librarium' is the old name for the client, and the database looks a little different now, but they give the general idea.
tags:




files: